好久没有写文章了
最近不是因为懒,而是因为确实太忙了,可能要等闲了以后再更新吧~
最近后台快被毛子的垃圾评论弄爆了,弄了个插件,现在会过滤所有非中文的评论,评论时请一定要带上一个中文符号。
黑名单列表:
所有西里尔字母
所有俄语网站URL
所有俄罗斯邮箱地址
所有超过3000字的评论
所有非中文评论
最近不是因为懒,而是因为确实太忙了,可能要等闲了以后再更新吧~
最近后台快被毛子的垃圾评论弄爆了,弄了个插件,现在会过滤所有非中文的评论,评论时请一定要带上一个中文符号。
黑名单列表:
所有西里尔字母
所有俄语网站URL
所有俄罗斯邮箱地址
所有超过3000字的评论
所有非中文评论
在团队进行漏洞利用的时候,发现对于mmap()返回的地址其实是处于一个可预测的状态的,mmap更偏向于选择一个最接近vma的地址,所以当只有攻击者能控制malloc而程序自身并不使用mmap分配时,vma会处于一个相对比较容易预测的位置,导致程序即使不知道malloc返回的地址,也可以有个相对高的可能性猜到某个位于mmap()之后区域的地址,这个ASLR绕过的问题就会比较麻烦。
而在lkml上也有相同的反馈,只不过在今年3月,这个问题已经有人提出来了,虽然还是在扯皮(到底是放在libc还是放在内核好),但是可以看一下思路。
From Ilya Smith
Subject [RFC PATCH v2 0/2] Randomization of address chosen by mmap.
Date Thu, 22 Mar 2018 19:36:36 +0300
当前实现不会将mmap返回的地址随机化。
所有熵的结尾都是基于在进程创建时选择mmap_base_addr。在此之后,mmap会产生非常可预测的地址空间布局。它允许在许多情况下绕过ASLR。此修补程序使mmap调用中的地址随机化。
v2:
改变了选择GAP的方式。现行的mmap版本中,没有试图得到所有可能的gap。在新版本中,将使用随机产生的地址,用作树的行走方向。
树采用回溯的方式遍历,直到找到合适的空隙(gap)时停止。当发现空隙时,地址从下一个VMA开始随机移动。
扩展了vm_unmapped_area_info结构,增加了新的字段random_shift ,可以用来在转移到下一个VMA开始时,设置与架构相关的限制值。
在x86-64体系结构中,32位应用程序的这种移动(shift)转换为256页,64位的为0x1000000页。
为了得到熵,代码采用了伪随机的方法。这是因为在英特尔x86-64处理器指令RDRAND在在大约10000次迭代之后(缓冲区被消耗)时工作非常缓慢。
这个特性可以通过设置randomize_va_space = 4来启用。(注:只是作者提议,似乎还没通过)
可以参看一下修改的具体内容:
Signed-off-by: Ilya Smith <blackzert@gmail.com>
---
arch/alpha/kernel/osf_sys.c | 1 +
arch/arc/mm/mmap.c | 1 +
arch/arm/mm/mmap.c | 2 ++
arch/frv/mm/elf-fdpic.c | 1 +
arch/ia64/kernel/sys_ia64.c | 1 +
arch/ia64/mm/hugetlbpage.c | 1 +
arch/metag/mm/hugetlbpage.c | 1 +
arch/mips/mm/mmap.c | 1 +
arch/parisc/kernel/sys_parisc.c | 2 ++
arch/powerpc/mm/hugetlbpage-radix.c | 1 +
arch/powerpc/mm/mmap.c | 2 ++
arch/powerpc/mm/slice.c | 2 ++
arch/s390/mm/mmap.c | 2 ++
arch/sh/mm/mmap.c | 2 ++
arch/sparc/kernel/sys_sparc_32.c | 1 +
arch/sparc/kernel/sys_sparc_64.c | 2 ++
arch/sparc/mm/hugetlbpage.c | 2 ++
arch/tile/mm/hugetlbpage.c | 2 ++
arch/x86/kernel/sys_x86_64.c | 4 ++++
arch/x86/mm/hugetlbpage.c | 4 ++++
fs/hugetlbfs/inode.c | 1 +
include/linux/mm.h | 1 +
mm/mmap.c | 3 ++-
23 files changed, 39 insertions(+), 1 deletion(-)
+unsigned long unmapped_area_random(struct vm_unmapped_area_info *info)
+{
+ struct mm_struct *mm = current->mm;
+ struct vm_area_struct *vma = NULL;
+ struct vm_area_struct *visited_vma = NULL;
+ unsigned long entropy[2];
+ unsigned long length, low_limit, high_limit, gap_start, gap_end;
+ unsigned long addr = 0;
+
+ /* get entropy with prng */
+ prandom_bytes(&entropy, sizeof(entropy));
+ /* small hack to prevent EPERM result */
+ info->low_limit = max(info->low_limit, mmap_min_addr);
+
+ /* Adjust search length to account for worst case alignment overhead */
+ length = info->length + info->align_mask;
+ if (length < info->length)
+ return -ENOMEM;
+
+ /*
+ * Adjust search limits by the desired length.
+ * See implementation comment at top of unmapped_area().
+ */
+ gap_end = info->high_limit;
+ if (gap_end < length)
+ return -ENOMEM;
+ high_limit = gap_end - length;
+
+ low_limit = info->low_limit + info->align_mask;
+ if (low_limit >= high_limit)
+ return -ENOMEM;
+
+ /* Choose random addr in limit range */
+ addr = entropy[0] % ((high_limit - low_limit) >> PAGE_SHIFT);
+ addr = low_limit + (addr << PAGE_SHIFT);
+ addr += (info->align_offset - addr) & info->align_mask;
+
+ /* Check if rbtree root looks promising */
+ if (RB_EMPTY_ROOT(&mm->mm_rb))
+ return -ENOMEM;
+
+ vma = rb_entry(mm->mm_rb.rb_node, struct vm_area_struct, vm_rb);
+ if (vma->rb_subtree_gap < length)
+ return -ENOMEM;
+ /* use randomly chosen address to find closest suitable gap */
+ while (true) {
+ gap_start = vma->vm_prev ? vm_end_gap(vma->vm_prev) : 0;
+ gap_end = vm_start_gap(vma);
+ if (gap_end < low_limit)
+ break;
+ if (addr < vm_start_gap(vma)) {
+ /* random said check left */
+ if (vma->vm_rb.rb_left) {
+ struct vm_area_struct *left =
+ rb_entry(vma->vm_rb.rb_left,
+ struct vm_area_struct, vm_rb);
+ if (addr <= vm_start_gap(left) &&
+ left->rb_subtree_gap >= length) {
+ vma = left;
+ continue;
+ }
+ }
+ } else if (addr >= vm_end_gap(vma)) {
+ /* random said check right */
+ if (vma->vm_rb.rb_right) {
+ struct vm_area_struct *right =
+ rb_entry(vma->vm_rb.rb_right,
+ struct vm_area_struct, vm_rb);
+ /* it want go to the right */
+ if (right->rb_subtree_gap >= length) {
+ vma = right;
+ continue;
+ }
+ }
+ }
+ if (gap_start < low_limit) {
+ if (gap_end <= low_limit)
+ break;
+ gap_start = low_limit;
+ } else if (gap_end > info->high_limit) {
+ if (gap_start >= info->high_limit)
+ break;
+ gap_end = info->high_limit;
+ }
+ if (gap_end > gap_start &&
+ gap_end - gap_start >= length)
+ goto found;
+ visited_vma = vma;
+ break;
+ }
+ /* not found */
+ while (true) {
+ gap_start = vma->vm_prev ? vm_end_gap(vma->vm_prev) : 0;
+
+ if (gap_start <= high_limit && vma->vm_rb.rb_right) {
+ struct vm_area_struct *right =
+ rb_entry(vma->vm_rb.rb_right,
+ struct vm_area_struct, vm_rb);
+ if (right->rb_subtree_gap >= length &&
+ right != visited_vma) {
+ vma = right;
+ continue;
+ }
+ }
+
+check_current:
+ /* Check if current node has a suitable gap */
+ gap_end = vm_start_gap(vma);
+ if (gap_end <= low_limit)
+ goto go_back;
+
+ if (gap_start < low_limit)
+ gap_start = low_limit;
+
+ if (gap_start <= high_limit &&
+ gap_end > gap_start && gap_end - gap_start >= length)
+ goto found;
+
+ /* Visit left subtree if it looks promising */
+ if (vma->vm_rb.rb_left) {
+ struct vm_area_struct *left =
+ rb_entry(vma->vm_rb.rb_left,
+ struct vm_area_struct, vm_rb);
+ if (left->rb_subtree_gap >= length &&
+ vm_end_gap(left) > low_limit &&
+ left != visited_vma) {
+ vma = left;
+ continue;
+ }
+ }
+go_back:
+ /* Go back up the rbtree to find next candidate node */
+ while (true) {
+ struct rb_node *prev = &vma->vm_rb;
+
+ if (!rb_parent(prev))
+ return -ENOMEM;
+ visited_vma = vma;
+ vma = rb_entry(rb_parent(prev),
+ struct vm_area_struct, vm_rb);
+ if (prev == vma->vm_rb.rb_right) {
+ gap_start = vma->vm_prev ?
+ vm_end_gap(vma->vm_prev) : low_limit;
+ goto check_current;
+ }
+ }
+ }
+found:
+ /* We found a suitable gap. Clip it with the original high_limit. */
+ if (gap_end > info->high_limit)
+ gap_end = info->high_limit;
+ gap_end -= info->length;
+ gap_end -= (gap_end - info->align_offset) & info->align_mask;
+ /* only one suitable page */
+ if (gap_end == gap_start)
+ return gap_start;
+ addr = entropy[1] % (min((gap_end - gap_start) >> PAGE_SHIFT,
+ 0x10000UL));
+ addr = gap_end - (addr << PAGE_SHIFT);
+ addr += (info->align_offset - addr) & info->align_mask;
+ return addr;
+}
+
unsigned long unmapped_area(struct vm_unmapped_area_info *info)
{
/*
--
2.7.4
不过还有一些Mixed content,这个主要Typecho的代码有点不兼容,后面看看怎么修改下做个适配……
linux的进程启动经过fork-execv之后,会将加载共享对象的工作交给ld去处理,ld会先进行自身的bootstrap,之后处理块。前面的就先跳过不看了,后面的以glibc-2.27的代码为准。
首先是DT_NEEDED的装载,进入的地方在elf/rtld.c的dl_main,不过暂时没必要细说这个,懒得打字了,直接向后定位,分别经过如下几层:
dl_main
|_ ( _dl_map_object_deps ) dl-deps.c
..|_ ( openaux ) dl-deps.c
....|_ ( _dl_map_object ) dl-load.c
......|_ ( _dl_map_object_from_fd ) dl-load.c
........|_ ( _dl_map_segments) dl-map-segments.h
而使用_dl_open的也是一样,会从_dl_open走到dl_open_worker(dl-open.c),然后到_dl_map_object_deps,后面都一样。
对_dl_map_segments的代码进行查看可以发现原因(注释机器翻译+人工润色,可能有不通的地方):
/* 这个实现假定(dl-unmap-secments.h中的_dl_unmap_段的对应实现也是这样)共享对象总是用所有连续的段(或者它们之间的间隙足够小,这样会优先用PROT_NONE映射将所有整页保留在gaps中,而不是允许使用地址空间的这些部分的其他部分)来布局共享对象。 */
static __always_inline const char *
_dl_map_segments (struct link_map *l, int fd,
const ElfW(Ehdr) *header, int type,
const struct loadcmd loadcmds[], size_t nloadcmds,
const size_t maplength, bool has_holes,
struct link_map *loader)
{
const struct loadcmd *c = loadcmds;
if (__glibc_likely (type == ET_DYN))
{
/* 这是一个位置无关的共享对象。
我们可以让内核将它映射到它喜欢的任何地方,但是我们必须保证所有内容相对于第一个对象有固定的空间。
因此,我们映射了第一段,但没有设置MAP_FIXED,随着范围的增加,它会覆盖到所有的段。
然后,我们从多余的部分删除访问,并且已知有足够的空间从后面的段重新映射。
还有一种完善措施,即:有时我们会有一个地址,我们希望将这些对象映射到这里;
但这只是我们的一种想法,操作系统可以做任何它喜欢的事情。
*/
ElfW(Addr) mappref
= (ELF_PREFERRED_ADDRESS (loader, maplength,
c->mapstart & GLRO(dl_use_load_bias))
- MAP_BASE_ADDR (l));
/* Remember which part of the address space this object uses. */
l->l_map_start = (ElfW(Addr)) __mmap ((void *) mappref, maplength,
c->prot,
MAP_COPY|MAP_FILE,
fd, c->mapoff);
if (__glibc_unlikely ((void *) l->l_map_start == MAP_FAILED))
return DL_MAP_SEGMENTS_ERROR_MAP_SEGMENT;
l->l_map_end = l->l_map_start + maplength;
l->l_addr = l->l_map_start - c->mapstart;
if (has_holes)
{
/* 更改多余部分的保护以禁止所有访问;以后不重新映射的部分将无法访问,就好像它们从未分配一样。
然后跳到正常的段映射循环中,处理文件映射结束后的段部分。 */
if (__glibc_unlikely
(__mprotect ((caddr_t) (l->l_addr + c->mapend),
loadcmds[nloadcmds - 1].mapstart - c->mapend,
PROT_NONE) < 0))
return DL_MAP_SEGMENTS_ERROR_MPROTECT;
}
l->l_contiguous = 1;
goto postmap;
}
/* 记住此对象使用的地址空间的哪个部分。 */
l->l_map_start = c->mapstart + l->l_addr;
l->l_map_end = l->l_map_start + maplength;
l->l_contiguous = !has_holes;
while (c < &loadcmds[nloadcmds])
{
if (c->mapend > c->mapstart
/* Map the segment contents from the file. */
&& (__mmap ((void *) (l->l_addr + c->mapstart),
c->mapend - c->mapstart, c->prot,
MAP_FIXED|MAP_COPY|MAP_FILE,
fd, c->mapoff)
== MAP_FAILED))
return DL_MAP_SEGMENTS_ERROR_MAP_SEGMENT;
postmap:
_dl_postprocess_loadcmd (l, header, c);
if (c->allocend > c->dataend)
{
/* 额外的零页应该出现在这个段的末尾,在文件映射的数据之后。 */
ElfW(Addr) zero, zeroend, zeropage;
zero = l->l_addr + c->dataend;
zeroend = l->l_addr + c->allocend;
zeropage = ((zero + GLRO(dl_pagesize) - 1)
& ~(GLRO(dl_pagesize) - 1));
if (zeroend < zeropage)
/* 所有额外的数据都在段的最后一页。我们可以把它设置为0。*/
zeropage = zeroend;
if (zeropage > zero)
{
/* 使段最后一页的最后部分为零。 */
if (__glibc_unlikely ((c->prot & PROT_WRITE) == 0))
{
/* Dag nab it. */
if (__mprotect ((caddr_t) (zero
& ~(GLRO(dl_pagesize) - 1)),
GLRO(dl_pagesize), c->prot|PROT_WRITE) < 0)
return DL_MAP_SEGMENTS_ERROR_MPROTECT;
}
memset ((void *) zero, '\0', zeropage - zero);
if (__glibc_unlikely ((c->prot & PROT_WRITE) == 0))
__mprotect ((caddr_t) (zero & ~(GLRO(dl_pagesize) - 1)),
GLRO(dl_pagesize), c->prot);
}
if (zeroend > zeropage)
{
/*从零填充FD处映射其余的零页。 */
caddr_t mapat;
mapat = __mmap ((caddr_t) zeropage, zeroend - zeropage,
c->prot, MAP_ANON|MAP_PRIVATE|MAP_FIXED,
-1, 0);
if (__glibc_unlikely (mapat == MAP_FAILED))
return DL_MAP_SEGMENTS_ERROR_MAP_ZERO_FILL;
}
}
++c;
}
/* 通知ELF_PREFERRED_ADDRESS,我们必须加载这个固定地址。 */
ELF_FIXED_ADDRESS (loader, c->mapstart);
return NULL;
}
相比于质量糟糕的openssl之流的代码,glibc的代码写得真的很好,注释十分完备,其实也没必要多打了,注释已经解释了第一部分的问题。
最近在调试一个漏洞,在利用信息泄露的洞的时候发现了一个比较好玩或者说和我预期不太一样的现象,即在Android或者Linux中,即使程序开启ASLR,DSO(Dynamic Shared Objects)的相对偏移却是固定的。即任意两个DSO加载位置的delta永远是固定值。除非中间有其他什么模块的干扰。
这就导致了一个问题:假如一个程序能够泄露某个模块的加载地址,那么就能够推算出其他所有模块的地址。而我的预期则稍稍有点不一样,我最开始是以为所有模块的加载都是随机的。
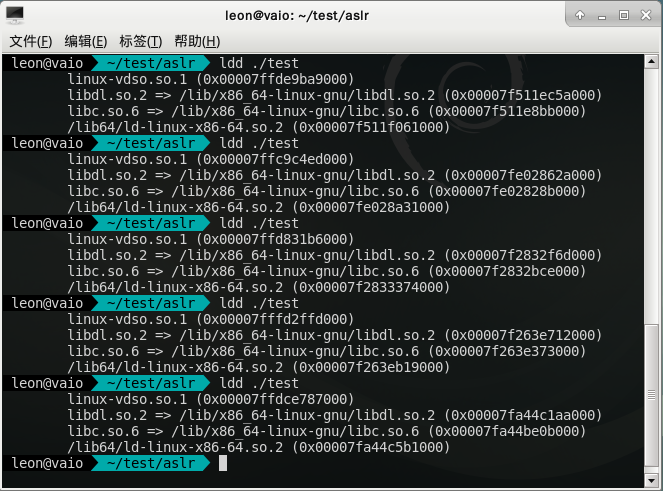
首先是标记为DT_NEEDED的模块,用ldd看可以发现,vDSO先不管,以libdl.so.2为基准,libc.so.6永远在它-0x39f000的地方,而ld-linux-x86-64.so.2则永远在它的+0x407000的地方。当然,这个只是我随便写的一个printf的程序,可能这几个库除了ld就是libc看起来比较“特殊”,但是对于其他程序而言,情况也是这样的。
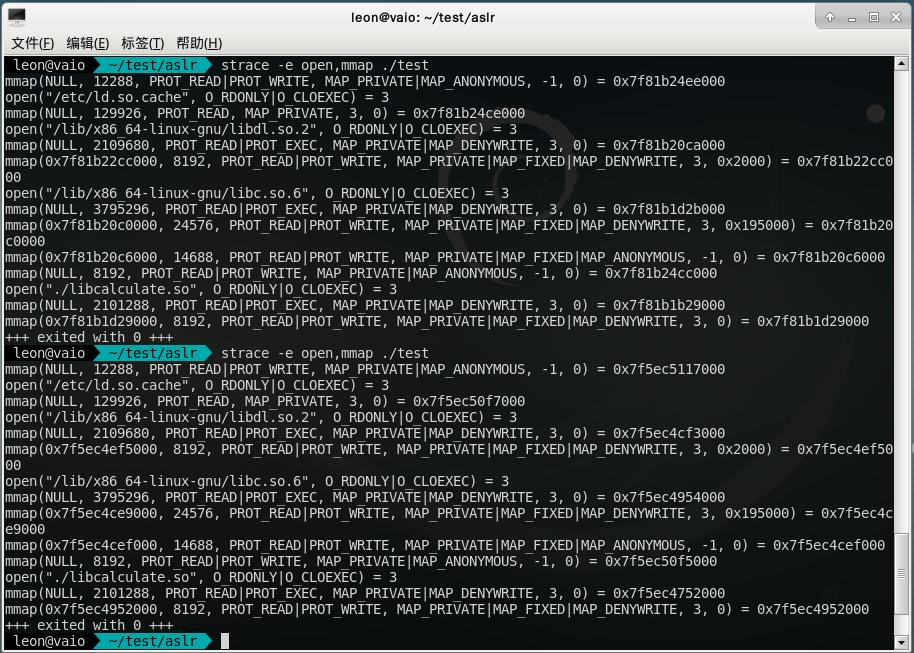
对于dlopen的加载也没什么区别,可以看到永远libcalculate.so都是在前一个模块的+0x39D000处。不管是LAZY还是RTLD_NOW,都是一样。
对它们进行检测,可以发现PIE都处于Enabled的状态。

所以比较迷茫的情况下看了下glibc的源代码(对,这一块是ld做的,ld的源代码事实上绝大部分情况下都在glibc,[或者其他什么库里面,如果开发者愿意修改的话]),似乎从中发现了一些线索。